


Managing a static fleet of strongDM servers is dead simple. You create the server in the strongDM console, place the public key file on the box, and it’s done! This scales really well for small deployments, but as your fleet grows, the burden of manual tasks grows with it.

Contents
Secure Access Made Simple
- Full Access to All Features
- Trusted by the Fortune 100, early startups, and everyone in between
This article will point you to the core concepts within a Security Incident Response Policy (SIRP) so that you understand the purpose of this policy, challenges, and tools to consider when writing your own.
What is a Security Incident Response Policy?
A Security Incident Response Policy (SIRP) is a set of processes and procedures a company establishes to detect and respond to security vulnerabilities and incidents. The primary goal is to minimize the impact of the incident, contain the threat, and restore normal operations as quickly as possible.
A SIRP is a critical component of an organization’s cybersecurity strategy. It establishes a structured and systematic approach to handling security incidents, helping the organization stay resilient in the face of cyber threats and ensuring the protection of sensitive data and assets.
Common Incident Response Challenges Faced By Organizations
Preparedness
It is important to have a well-documented and tested incident response plan where all the stakeholders are identified and everyone understands their role and responsibilities. Without this, teams may struggle to respond promptly and effectively when an incident occurs.
Inadequate Detection Capabilities
Organizations may lack the necessary tools and technologies to detect incidents in real-time. Without robust monitoring and observability tools, suspicious behavior can go undetected for extended periods, putting you at risk for significant damage.
Evidence Collection
Properly preserving and analyzing audit logs is critical for understanding the scope and impact of an incident.
Alert Fatigue
If a trigger is too sensitive, you risk alert fatigue, which can erode confidence or suppress the notification of a real incident.
Addressing these challenges requires a proactive approach to incident response. Organizations should invest in incident response planning, regular training and simulations, and effective communication structures to enhance their incident response capabilities.
Potential Consequences Of Inadequate Incident Response Policies
Data Breaches and Loss of Intellectual Property
Inadequate incident response policies may lead to prolonged exposure to cyber threats, resulting in successful data breaches or the loss of valuable intellectual property. This can have severe financial and reputational implications for the organization.
Financial Loss
Security incidents can lead to financial losses in various ways, including direct costs associated with incident response, legal fees, regulatory fines, and compensation to affected parties.
Legal and Regulatory Consequences
Failure to have an effective security response policy in place can result in non-compliance with data protection and privacy regulations, leading to legal actions and regulatory penalties.
Reputational Damage
A poorly managed security incident can damage the organization's reputation and erode trust among customers, partners, and stakeholders. Negative publicity and public perception can lead to a loss of business and opportunities.
Loss of Competitive Advantage
A data breach or security incident can compromise a company's competitive advantage by exposing sensitive business strategies, research, or other proprietary information.
Downtime and Disruptions
Inadequate incident response may lead to prolonged downtime and disruptions to business operations, impacting productivity and revenue generation.
Intellectual Property Theft
Inadequately protected intellectual property can be stolen or compromised, leading to loss of innovation and competitive edge in the market.
Increased Insurance Premiums
Organizations with inadequate security response policies may face higher insurance premiums due to increased risk perception from insurers.
To mitigate these consequences, organizations must prioritize cybersecurity, develop robust and tested incident response policies, invest in security measures, regularly update their security posture, and ensure compliance with relevant regulations and industry standards. A proactive and well-prepared approach to security can significantly reduce the impact of security incidents on an organization.
9 Tips for an Effective Security Incident Response Policy (SIRP)
- Work to continually refine your threshold between security alerts and security incidents.
- In the case that an incident is resolved as a false positive, use what you learned from it to further tune your alert threshold.
- Incident reporting can be conducted with a system your team is already using, such as Slack or Teams.
- Have an incident response team (often called a Computer Security Incident Response Team or CSIRT) on retainer to help in case of an emergency.
- Provide relevant information to the incident response team so they can be as prepared as possible should you require their services.
- Beneficial information to a CSIRT may include network diagrams, copies of your policies and incident response plan, asset inventory and IP addresses, and contact information for the chief information officer (CIO) and/or other leadership.
- Verify whether incident response team members have technical infrastructure in place to help you prepare for common attacks, such as DDoS (distributed denial-of-service attacks).
- A CSIRT can also advise on tabletop exercises to practice to better prepare you for a data breach, even something as straightforward as running through your backup and restore process.
- Test the SIRP regularly, and strive to keep it as simple yet comprehensive as possible.
Introducing StrongDM for Security Incident Response
StrongDM is a Zero Trust Privileged Access Management (PAM) platform that centralizes privileged access for all technical users to every database, server, cluster and cloud resources in your infrastructure. Every activity and query is logged for complete monitoring and observability, so you have fast and accurate answers during incident investigations and audit reviews.
Key features and capabilities relevant to incident response
1. Centralized access control and policy enforcement2. Real-time monitoring and audit logging
💡Make it easy: StrongDM can provide total visibility into activities that have happened in your stack. Security and Compliance teams can easily answer who did what, where, and when. Try it yourself.3. Incident detection and alerting mechanisms
4. Integration with incident response tools and workflows
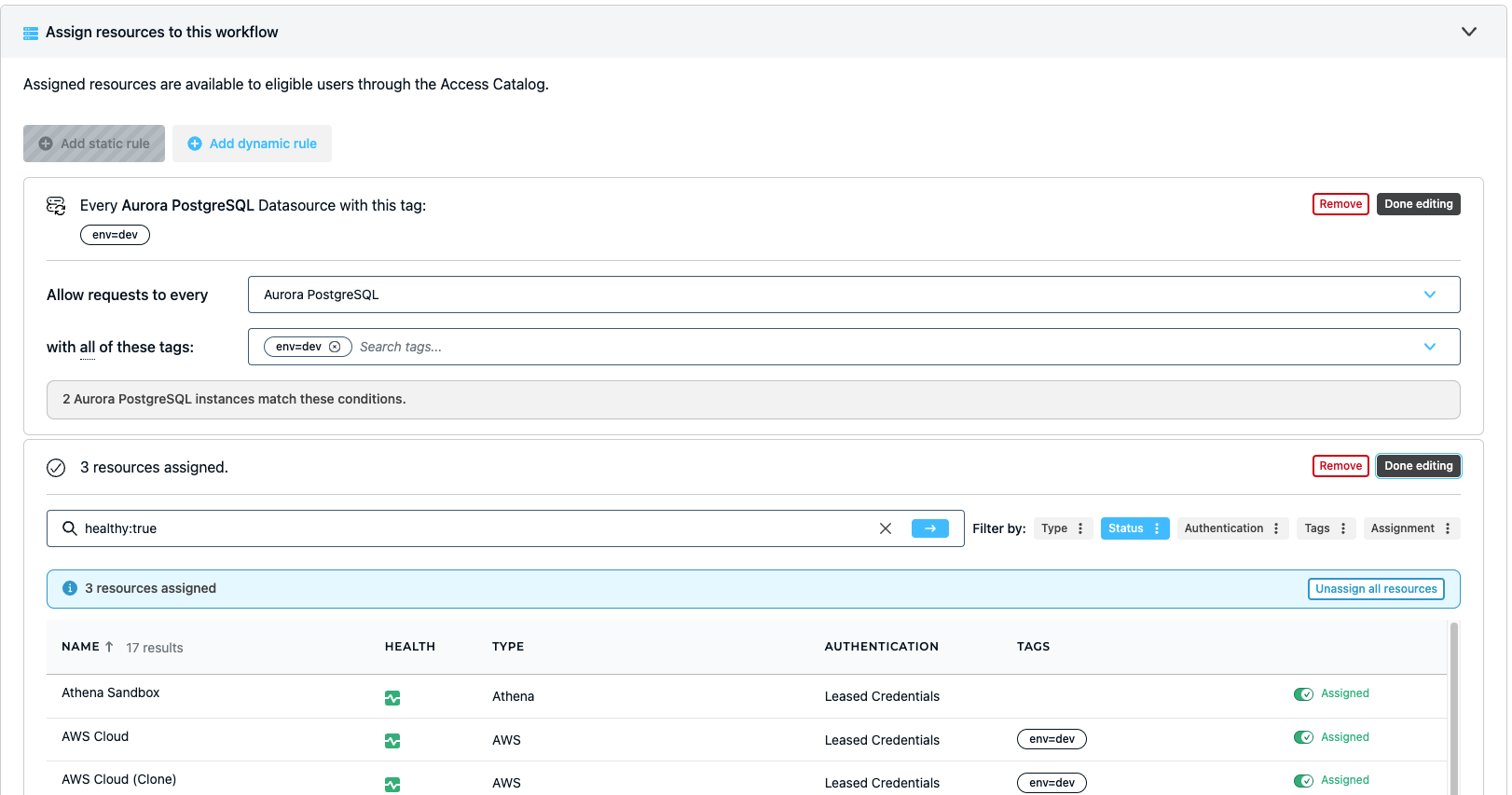
5. Streamlined access revocation and role-based access control
💡Make it easy: StrongDM allows you to create dynamic access rules to implement attribute-based access control. Create tags for regions or environments so only a certain role can request access to critical environments like prod. Try it yourself.
Benefits of Using StrongDM for Incident Response
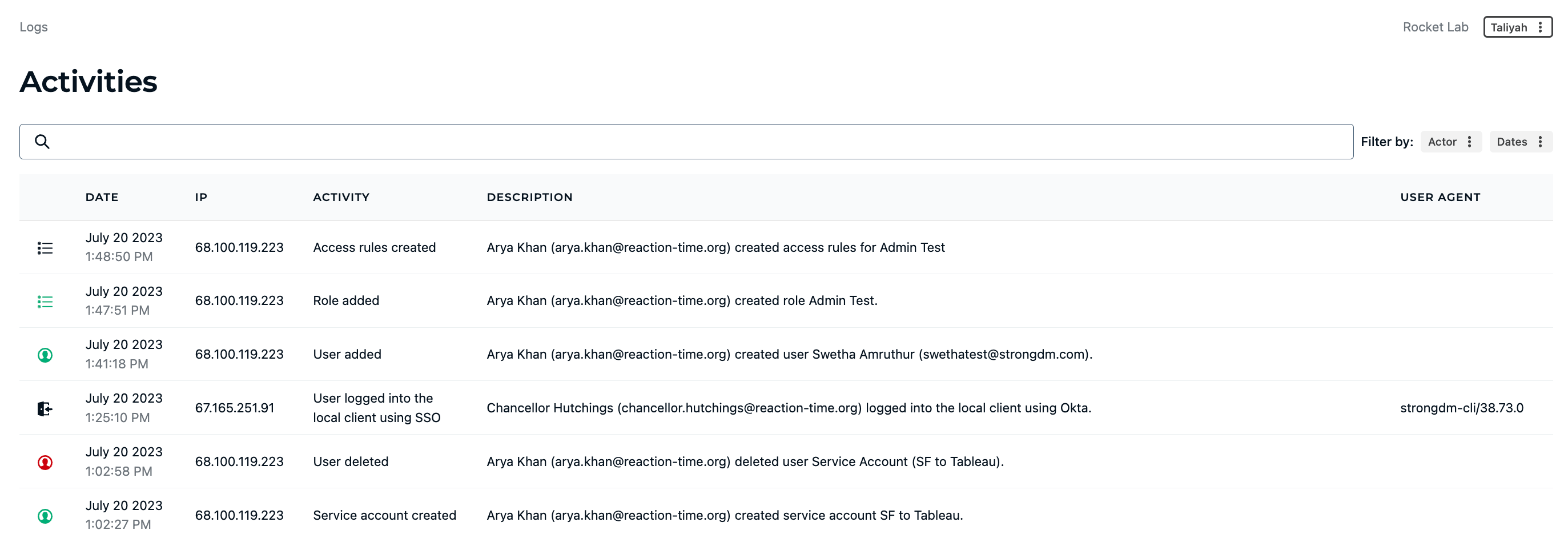
- Improved incident detection and response time: Centralized logs for activity and query across all of your infrastructure ensures that nothing is missed. Every last granular detail is logged and exported to your observability tool of choice. Any suspicious activity? Access can be revoked in real-time to stop an attack in its tracks.
- Enhanced visibility and auditability of access activities: All user activity and query is logged, with playback sessions available for SSH, RDP, and Kubernetes.
- Efficient coordination among incident response team members: Incident response teams are able to get access to resources based on their roles.
- Streamlined access management during incident investigations: Investigators get timely access to resources they need to perform an investigation
Implementing StrongDM for Security Incident Response
StrongDM enables incident response teams to improve mean-time-to-investigate (MTTI) and mean-time-to-respond (MTTR). With precise controls, access can be granted by role or with just-in-time workflows. When an incident response team is alerted, StrongDM can define a role or automate workflows for incident response team members to grant access to resources.
StrongDM offers integrations with tools like PagerDuty to automate access when users are alerted of a security incident. Access to resources can be immediately revoked when the investigation is over.
In addition to access, StrongDM helps with forensic investigation. Granular audit logs show exactly who accessed what and when. This means that during discovery, it is easy to pinpoint exactly who had access to particular resources when an alert is triggered. Investigators can review every activity and query logs, as well as playback recorded sessions.
StrongDM can also support a broader incident response strategy which includes SIEM/SOAR and incident alerting tools. A comprehensive SIRP also includes proper planning, documentation, and coordination among relevant teams to effectively address and resolve the incident.
Case Study: Successful Implementation of StrongDM for Incident Response
StrongDM helped CaseWare with incident response times by streamlining access and capturing every query. StrongDM’s integration with PagerDuty allows efficient responses to alerts and automates access. Forensic investigations are also much easier with the ability to playback sessions quickly.
“StrongDM is a must-have for a cloud-native team. The time savings were noticeable on day one. That’s what matters to our team and what we’ve been tracking.”
- Nicholas Skoretz, Cloud Infrastructure Engineer, CaseWare (source)
Conclusion
A robust security incident response policy is crucial for organizations to effectively detect, manage, and resolve security incidents. These policies ensure that when incidents occur, the right actions are taken promptly, minimizing potential damage and reducing downtime. With its centralized access controls and audit trails, StrongDM simplifies access management and provides a comprehensive view of user activities, aiding in reconstructing events during investigations.
StrongDM empowers teams to respond swiftly to incidents, control access to critical systems, and maintain a proactive security stance, ultimately bolstering their overall cybersecurity posture.
See StrongDM in action, book a demo.
You May Also Like

Offboarding technical employees can be a complex and arduous process with a lot of moving parts. The key to successful offboarding is to have a clear understanding of what needs to be done, who does it, and how to monitor for any shenanigans from former employees.

There are a number of ways to automate user provisioning but the real challenge lies in keeping track of those credentials.

As your organization pursues your SOC 2 certification, organization is critical. You will be busy actively managing dozens of ongoing daily tasks, which can bury you in minutiae. But at the same time, you need to keep your high-level compliance goals in focus in order to successfully move your certification over the finish line.
