

As AI agents take on actions once performed only by humans, traditional identity systems can’t provide clear delegation or accountability. StrongDM ID gives every agent a unique, verifiable identity linked to a human sponsor, ensuring organizations always know who authorized every action. In the next era of identity, authentication matters—but delegation defines trust.

Contents
Secure Access Made Simple
- Full Access to All Features
- Trusted by the Fortune 100, early startups, and everyone in between
If you manage any system that requires consistent availability, then you are probably already familiar with services like PagerDuty. For those of you who are unfamiliar with on-call management, it is a class of services that integrates with your monitoring and alerting systems to ensure that someone gets notified of issues promptly.
Typically there is a team that shares the responsibility of being on call on a periodic rotation. Being the first responder for production incidents typically requires an elevated set of permissions to ensure that they are not hampered in their efforts to get your services back online.
Principle of Least Privilege
For day-to-day situations, you don’t want to grant admin access to all of your servers for every engineer. Instead, it is prudent to follow the principle of least privilege when allocating permissions. The basic idea is that every user should only have access to the resources that are required for them to complete their assigned tasks and everything else should be restricted. The benefit of this approach is that it reduces the potential impact of lost credentials or a successful phishing attack.
Managing On-Call Staff Permissions
A naïve approach to the problem of granting administrative access to your on-call staff is to have a single set of credentials with administrative permissions, either per user or that get shared with whoever is scheduled. The problem with this is that there is no way to ensure that those credentials aren’t being used outside of their intended context.
An alternative is to synchronize your on-call schedule with your access control. This can take a few forms, depending on how you manage credentials, which we will explore for the rest of this post.
Automating On-Call Staff Access
Scripts
A non-exhaustive list of ways to grant admin permissions to your on-call staff includes things such as a script that generates short-lived credentials, a script that elevates permissions on existing credentials, or (in the case where you have role-based access management) modifying the role of an existing user. Each of these approaches has tradeoffs that are worth considering.
In the case of scripting credential access, your logic would probably look like this pseudo-code
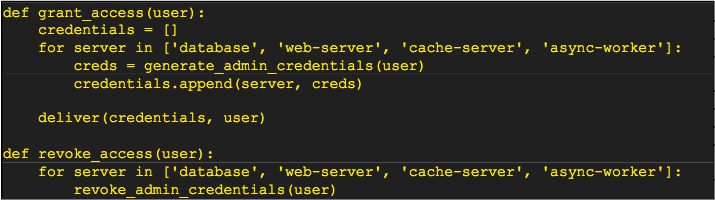
One of the issues that this example punts on is how those credentials get delivered. A reasonable approach that doesn’t require a massive amount of effort would be to encrypt the bundle of credentials with the user’s GPG key and then send that encrypted bundle via email or a file share. While that is fine, it is not exactly the easiest experience. Another item that is omitted is how and when this code gets called. As you are first getting started, you might run it manually, but if the rate of turnover for on-call schedules is reasonably frequent, then that approach will quickly become monotonous, encouraging you to asymptote toward a single set of static credentials for each user, which, as we already discussed, is not ideal.
Another question is how the credentials for that user are tracked for revocation at the end of their shift. A lightweight method would be to set their username to be the same on each system or to deterministically generate a value, such as with the SHA256 hashing function.
One optimization for this method is to upgrade access for the given user and then downgrade it at the end of their shift. This at least eliminates the need to deliver a new set of credentials each time, but the logic for managing those permissions can become quite complex for different systems depending on how their authorization functionality is defined.
While this approach is viable for small teams and systems that don’t experience a high rate of churn, it can quickly become a maintenance burden. One way to at least remove the manual effort needed for this approach is to encapsulate some of this logic behind a web API that gets called automatically on schedule changes. This at least removes the possibility of someone forgetting to run the necessary script, but the code itself will still need to be properly maintained as servers, and users get added and removed.
Secrets Server
Another means of automating credential access is to rely on a service such as Vault from Hashicorp or the AWS Secrets Manager. These platforms allow you to define a profile for each server and database that you manage that will generate a set of credentials on request. By granting the necessary permissions to those roles or profiles, your engineers will be able to gain the access that they need to perform their job. When they are on call, you assign access to the admin level profiles to allow elevated access during an incident.
The benefit of using this type of service is that it handles credential expiration and rotation on your behalf. Creating the profiles to generate short-lived accounts frees you from worrying about whether they are being used outside of their intended purpose. The initial setup for these services can be complex, but once they are in place, they make authorization more manageable.
Unfortunately, this approach does not provide an audit trail for what staff do during a session. While you can state with confidence that a user was granted access, you won’t be able to log any specific database queries, ssh, RDP, or kubectl commands.
Access Proxy
The third class of solutions is to delegate all of the permissions management to an access proxy. In this scenario, the user never gains direct access to the credentials being used, and instead relies on their existing account on the proxy, meaning that there is no setup cost during their scheduled rotation.
As an example, StrongDM uses RBAC (Role-based Access Control) to determine which permissions each user can be granted. It also has a concept of temporary access, allowing administrators to assign specific database or server access to a user for a specific time period, after which the grant automatically expires, and the user’s access is removed.
One way to take advantage of temporary access is to automate it with a chatbot: StrongDM uses a Hubot integration to automatically request and grant temporary access to sensitive internal databases and servers. The code looks something like this:
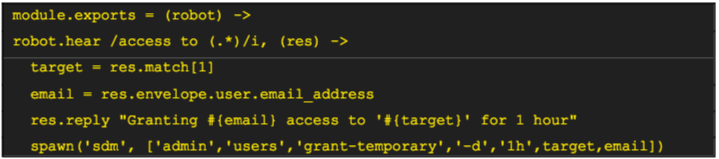
Users with access to this bot can thereby request temporary access to production systems, and each grant is logged in the StrongDM audit log for later review.
By integrating this method of automated temporary access with your pager service, you can automatically grant a new role to your users while they are on-call and then remove it when they are cycled back to their normal duties.
Tying It All Together
Throughout this post, I repeatedly mentioned integrating the various approaches to access control with your on-call schedule but neglected to call out how that would work. Because each on-call management service has its own API, I am going to focus on PagerDuty for the purposes of illustration.
The simplest approach is to use the PagerDuty on-call API as part of a script that runs on a schedule (e.g., via Cron). Querying that endpoint will return the full list of who is currently scheduled for the different priority tiers. Iterating over the results and updating or generating access credentials is all that would be needed, as illustrated in this pseudo code.

An optimization that can be made is to only grant elevated permissions during an incident by taking advantage of the incident webhook. Taking it further, by parsing the contents of the incident report, you could optionally only grant permissions to the affected server(s), but with complex systems, that may prove to be a hindrance rather than a help if the actual cause of the issue is located in a different portion of your environment.
Conclusion
However you manage access to your infrastructure and ensure that your on-call staff has the permissions that they need when they need them is critical to ensure that you can recover in a timely fashion. At the same time, exercising the principle of least privilege is prudent to avoid accidental errors due to unnecessarily elevated privileges.
To get started with StrongDM and grant temporary access with ease, and automate your team's on-call access start your 14-day free trial now or book a no BS demo with the team.

Categories:
You May Also Like

As AI agents take on actions once performed only by humans, traditional identity systems can’t provide clear delegation or accountability. StrongDM ID gives every agent a unique, verifiable identity linked to a human sponsor, ensuring organizations always know who authorized every action. In the next era of identity, authentication matters—but delegation defines trust.

The modern cloud is fast, dynamic, and complex. But legacy security tools can’t keep up. As containers and ephemeral resources constantly change, and access requests surge, security teams are left scrambling. Entitlements pile up, visibility fades, and audits become a nightmare.

The modern cloud is fast, dynamic, and complex. But legacy security tools can’t keep up. As containers and ephemeral resources constantly change, and access requests surge, security teams are left scrambling. Entitlements pile up, visibility fades, and audits become a nightmare.
