

StrongDM’s Next-Gen Kubernetes provides secure, seamless access to Kubernetes clusters at scale. By eliminating standing privileges and enforcing Zero Trust security principles, StrongDM helps security teams maintain tight access controls without slowing down DevOps workflows.

Contents
Secure Access Made Simple
- Full Access to All Features
- Trusted by the Fortune 100, early startups, and everyone in between
When an information security incident occurs, you need to be able to gather as much information about it as quickly as possible. There’s also a very real possibility that you will have to involve outside parties - such as an incident response team - to help you as well.
This means you can’t approach log management and retention as simple items on a checklist. Instead, you must have rich data captured within audit logs from all critical information systems. Otherwise, your logs will be incomplete, inaccurate, or missing altogether — which doesn’t provide you the historical information you need when cybersecurity questions, concerns, or incidents arise.
Scrambling to gather log data for your incident response team delays your efforts to stop a malicious actor, leaving your systems vulnerable. When it comes to security intelligence, you don’t have time to waste.
🕵 Learn how Coveo gained complete visibility across their entire stack with centralized and granular audit logs and simplified compliance audits.
5 questions to ask when writing your log management and review security policy
Are your event logs complete and accurate?
It’s 10 p.m. - do you know what’s connected to your network? If you have had an IT or security audit in the past, you may have heard a saying similar to, “You cannot protect what you do not know is there.” It may sound simple or silly, but it’s true. There’s no way to know if you are gathering logs from all your endpoints and operating systems unless you complete a comprehensive software and hardware inventory. This is why many security assessment frameworks set this as a high-priority finding. The CIS Critical Security Controls (CSC), for example, put “Inventory and Control of Hardware Assets” as number one on their list.
What should audit logs contain?
It’s not enough to simply be collecting logs. You might be filling terabytes of hard drive space with logs from your intrusion detection system and anti-virus solution as you read this post right now, but you could miss critical information if the security logs don’t capture answers to these questions:
- What happened? What are the relevant error messages, event IDs, etc. that speak to the security event?
- What systems are affected? Do logs collect relevant system names and IP addresses?
- When did it happen? Are all critical security systems, such as your intrusion prevention systems, synchronized with a centralized time source? And is the time zone set appropriately on all endpoints as well?
- Who was logged in? Are events tied back to a unique user ID?
Although this core information will give you a fighting chance to accurately triage and respond to issues, it’s the “who” question that is of particular importance in the world of SOC 2. This goes beyond just understanding who had access to the system — you also need to know exactly what they were doing at 2pm on December 16th when the system went down. Look at other activities of that individual that might be connected to the incident— and verify which activities were within their access permissions.
This kind of information is at your fingertips when you have a tool that creates comprehensive system log files of:
- When a new user is provided with a system account
- When an account has access control granted or suspended, and by whom
- When an account accesses sensitive information, such as data associated with PCI DSS and HIPAA
- When an account shows signs of malicious activity, such as deleting large quantities of files or disabling security monitoring software
- When accounts change roles or permission levels
- When system administrators/engineers make changes to databases or servers
Audit trail
In addition to collecting the critical logging information, you need the ability to store it in a format that makes sense for auditing purposes. Some companies just turn “logging up to 11” and what they essentially end up with is a gigantic pile of logs. But if someone had to actually search and parse through those logs, it would be a living nightmare. Whatever tools you use to ingest logs need to have advanced searching capabilities. You need to be able to search by key fields and indicators, as well as run reports from a specified timeframe, as these are the kinds of operations, you will be asked to do during an audit.
🔥Hot Tip: Many legacy logging tools use screen recordings to capture logs. Find a tool like StrongDM that records your logs with text search abilities— this will get you to the information you need much faster.
How long should audit logs be kept?
As you might imagine, this amount of real-time log data needs to be retained for a period of time to satisfy audit and/or regulatory requirements. As a general rule, storage of audit logs should include 90 days “hot” (meaning you can actively search/report on them with your tools) and 365 days “cold” (meaning log data you have backed up or archived for long-term storage). Store logs in an encrypted format. See our post on Encryption Policies for more information.
How often should audit logs be reviewed?
Remember that just collecting the logs is not enough. You need to periodically review logs for unusual behavior, which can come from a combination of automatic and manual efforts. Your logging/alerting/correlation system, for example, can be configured as a first-level triage for uncovering unusual behavior. But tools shouldn’t be the be-all, end-all of your log review. You should configure log summary reports that are automatically emailed periodically and then assign resources to review them monthly. During the manual review, you can ensure the log collection endpoints match up with your inventory and configure any new endpoints to generate logs as needed. You can also figure out if one or more log sources are failing to collect for any reason and/or if log disk space for the next month will be sufficient.
It’s also a good idea to schedule regular simulations of events to make sure the proper logs are generated. For instance, you could create a test account on the network, adjust its rights and permissions, and then log into it with the wrong password enough times to force a lockout. Ensure that logs were generated for each of these key events, and gave you enough information to answer the questions above.
Many organizations have no idea what’s going on “under the hood” of their networks, and in the case of a breach or other security incident, they would have little evidence to help them figure out what happened. Turning up logging from your network endpoints is a great first step, but you also need to tune the logs so they provide you with insightful information. Make sure you have carefully planned for storing these logs for both the short and long term. Finally, be sure that you don’t rely solely on your tools to shoulder the logging burden for you. Schedule regular manual reviews to make sure all critical endpoints are being logged and generate the level of detail that you define in your log management and review policy.
Why are audit logs important?
First reason: Legal Requirements
Some regulated environments require that access and action on a database be tracked.
The image below is a capture of version 3.2.1 of the PCI DSS standard:
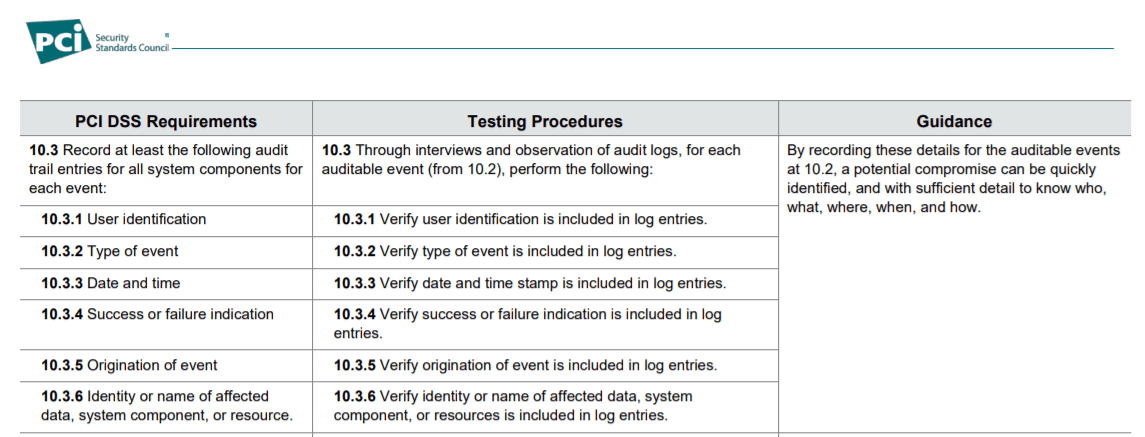
✨ Stay on Top of It: The requirements for PCI compliance are dependent on the number of transactions your business processes, which means the difficulty of maintaining compliance grows as you grow. Download our PCI Compliance Checklist to make sure you don’t fall behind.
For health data, the Nationwide Privacy and Security Framework for Electronic Exchange of Individually Identifiable Health Information is a bit less prescriptive, but the obligation results in a good audition system in place:
“Persons and entities should take reasonable steps to ensure that individually identifiable health information is complete, accurate, and up-to-date to the extent necessary for the person’s or entity’s intended purposes and has not been altered or destroyed in an unauthorized manner.”
This one is interesting because it brings up an important reason to audit your system queries: ensuring data integrity. It would be easy to assume that data is safe if access is restricted to staff in clearly defined roles. After all, you only hire professional and trustworthy people.
But in this day and age, it’s critical to take this a step further — trust but verify. This requires that you collect forensic evidence. If someone claims their data has been improperly accessed or tampered with, you need a proper log management solution to prove their claim is false. To do that, your system must log every action, not just the security logs. For example, application logs and operating system logs may contain security-related information as well as log messages about events that may not initially appear security-related. The potential value of different sources and log events must be considered. Furthermore, it’s not sufficient that log entries demonstrate the following:
- access to applications, databases, or servers is restricted to specific people or roles
- only these staff had sessions on a given day
- these commands were executed but by a shared credential, so there is no clear authorship
Your log management setup needs to provide for all three to answer who did what, where, and when.
Second Reason: Data Integrity
Ensuring data integrity means doing a lot of things, A LOT! This doesn’t just mean you have to backup data and set proper access control to prove it hasn’t been tampered with. You also need to track all changes to records to demonstrate that nothing was modified post ingestion from an external data source (client input, as form, mail, or upload, for example).
You must be able to prove that no system administrator or developer has modified the data from the original input. To do that log analysis, you need to log data from both human and machine interactions.
When humans interact with data, sometimes that occurs in your application. In those cases, activities should be tracked in the application logs themselves. Other times, humans might query a database or ssh to a web server containing sensitive data. In those cases, you will need another approach to log information from those sessions, queries, and commands.
We can all agree that in an ideal world, no one would access the DB, and all changes would run through a deployment pipeline and be subject to version control. In reality, that is not always true. Sometimes just finding what went wrong in code implies connecting to the database to investigate. Without a record of the queries during that session, you would be unable to prove what that developer did.
Third Reason: Forensic analysis
This is the most important reason to create audit logs, especially for databases and servers. While most engineering teams claim to do “blameless postmortems,” it is impossible to conduct a postmortem without an event log of who issued each query. That way, you know what happened and how to roll back.
One way to achieve that is to force all developers to query through an IDE or SQL interface. However, what is missing is a code error from an ORM framework on a developer workstation. This kind of generated queries are hard to guess from the object code and can prove to be a headache to reverse engineer to fix a casual error where the workstation has used the production DB instead of QA, or just because a fixed code had an oversight side effect when correcting a bug, there are too many cases to name them all and the usual quote “If it can happen, it will happen, the question is When?” Then you must ask, “when it happens, how do you plan to recover.”
Some version of these problems occurs pretty regularly. Sometimes the answer is just to restore, even if it includes sensitive data loss. In the best case, this leads to a useful postmortem, as Gitlab has done a few years back.
Fourth Reason: Because You Can 🙂
Now I know we all should follow log management best practices, but my mother also said I should eat spinach (spoiler alert, I did not). Why? Because best practices are hard. I’ve insisted that queries & ssh commands should be logged because they’re simpler to argue about. But the list of important commands goes well beyond these two. It also includes your system settings. For example, tinkering with the system clock or configuration could cause a fair amount of problems as well.
There are several ways to create that audit trail, including:
- creating a bastion host
- enabling database logs (See more about PostgreSQL logging best practices)
These DIY approaches take some work to build and maintain, but they’ll do the trick. If you have the budget, try StrongDM. StrongDM eliminates the PAM and VPN hell with a protocol-aware proxy that secures access to any database, Linux or Windows server, k8s, or internal web application.
From my experience, StrongDM provides a straightforward and secure approach to gateway audit systems. It doesn’t solve all problems, of course, but it does a good job covering the bases I mentioned above with JSON logs that are easy to parse and consolidate. Another benefit to logging via StrongDM is that they allow you to identify long-running queries which may have impacted application performance. Once you’ve figured out the queries causing performance degradation, you can refactor them to be more effective or schedule them in a low activity timespan.
💡Make it Easy: With StrongDM’s report library, you can see exactly who is doing what, when they are doing it, and where it is being done. This is a huge time saver when completing audits — you won’t even break a sweat. This also enables you to execute internal audit checks more frequently so you can catch security issues earlier (and finally finish work before 5pm). Get a refresher on the StrongDM report library here.
There are also other benefits to using StrongDM. Using it to secure user access gets you not only comprehensive log files but one-click user onboarding and offboarding, audit of access permissions at any point in time, real-time streams of queries in the web UI, and fully replayable server and k8s sessions. It’s a comprehensive suite of tools to manage access to your internal resources.
Try StrongDM with a free 14-day trial.
To learn more about how StrongDM helps companies with auditing, make sure to check out the Auditing Use Case.

Categories:
You May Also Like

Kubernetes observability is the practice of monitoring and analyzing a Kubernetes environment through metrics, logs, and traces to gain visibility into system performance and health. It enables teams to detect and resolve issues proactively, optimize resource utilization, and maintain cluster reliability through real-time insights and automated monitoring tools.

Audit logging is essential for maintaining a secure and compliant IT infrastructure. By capturing detailed records of system activities, audit logs provide insights into user actions, system events, and potential security threats. Understanding audit logging helps you identify and address vulnerabilities, ensure regulatory compliance, and enhance overall system integrity.

In this article, we will spotlight 11 log management best practices you should know to build efficient logging and monitoring programs. You’ll learn how to establish policies and take a proactive approach to collecting, analyzing, and storing business-critical log data. By the end of this article, you’ll have a clearer understanding of how logs can help security teams detect suspicious activity, address system performance issues, identify trends and opportunities, improve regulatory compliance, and mitigate cyberattacks.

Two of the most important questions in security are: who accessed what, and when did they access it? If you have any Linux or Unix machines, you’ll likely find answers in the sshd log. sshd is the Secure Shell Daemon, which allows remote access to the system. In this article, we’ll look at how to view ssh logs.